토스 SLASH 22를 보고 관심 있는 주제인 Server/DevOps 위주로 정리했습니다.
소위 말하는 네카라쿠배의 컨퍼런스를 보면서 느끼는 것 중 하나는 대용량/동시성 처리를 위해서는 아키텍처와 생각의 패러다임 전환이 필요하고, 인프라의 재설계 및 운영 방법에 대한 고민도 필수적이라는 것입니다.
그리고 필연적으로 높은 운영 난이도가 요구되기에, 과도기의 회사에서는 어디까지를 트레이드 오프 해야 할지 항상 고민됩니다.
지속 성장 가능한 코드를 만들어가는 방법
- 패키지를 잘 관리함으로써 코드의 응집성을 높일 수 있습니다.
- import를 정리하는 것 또한 클린 코드의 영역입니다.

- 레이어 참조는 한 방향으로 이루어져야 하며, 레이어 역류와 레이어 건너뛰기는 금지됩니다.
- 멀티 모듈을 통해 레이어를 격리시킬 수 있습니다.
지금은 레이어 역류의 위험성을 알고 있지만, 처음에는 잘못된 줄도 모르고 반복하던 실수 중 하나입니다.
이를 막기 위해 모듈을 분리하거나 레이어 간의 메시지 전달을 엄격히 분리된 dto로 하는 방법 등이 있지만, 보일러 플레이트가 많아지고 지금의 규모에서 고민해야 될 문제인가? 를 고민하게 만드는 주제이기도 합니다.
코드 리뷰어 활동을 하면서 남긴 글을 공유합니다.
https://hyune.gitbook.io/hyune-wiki/and/codesquad/22reviewer/undefined/service-dto
토스뱅크의 완전히 새로운 대출 시스템
- MSA 아키텍처 도입
- flyway를 통한 DB 스키마 관리
- ddl-auto 옵션을 validate로 설정하여 prod 배포 시 2차 확인.
- 각각의 대외기관은 TPS가 다르기에 독립적인 유량 제어를 위해 카프카와 파이프라인을 활용합니다.
- 정확한 TPS 측정을 위해 API 통신은 동기로 처리합니다.
- resdis에 지표를 저장하고, rdb에 분 단위의 통계를 저장하는 방법으로 유동적인 서킷 브레이커를 구현했습니다.
- 서킷 브레이커로도 감당되지 않는 경우 대기열을 활용합니다.
유량 제어와 서킷 브레이커에 대해 다시 한번 정리할 수 있었습니다.
특히 대기열까지 활용하는 것은 생각하지 못했는데 좋은 인사이트를 얻었습니다.
왜 은행은 무한스크롤이 안되나요
계정계는 고객의 거래 데이터를 다루는 영역으로 높은 신뢰도가 필요합니다.
채널계는 기능 요청의 포인트로 계정계에 비해서는 상대적으로 낮은 신뢰도를 가집니다.
- 토스에서는 계정계의 정보를 채널계에서도 가지고 있는 방식을 선택했습니다.
- 예외 처리 흐름을 상정하고 카프카를 활용해 거래내역을 동기화했습니다.
요약
- 빠른 거래내역 조회를 위해 채널계에 거래내역을 적재
- 채널계에서 적재된 거래내역을 이용해 중복 송금 방지
- 카프카를 이용해 계정계와 채널계 사이의 거래내역을 동기화
- 만약의 경우를 대비해서 수동 동기화 제공
최근 회사에서도 비슷한 성격의 업무에 대해 고민하고 있기에 재미있게 봤습니다.
다행히도 제가 생각해낸 아이디어와 영상에서 말하는 계정계 원장의 정보를 채널계에서도 가지고 있는다가 같아 재미있었습니다.
토스증권 실시간 시세 적용기
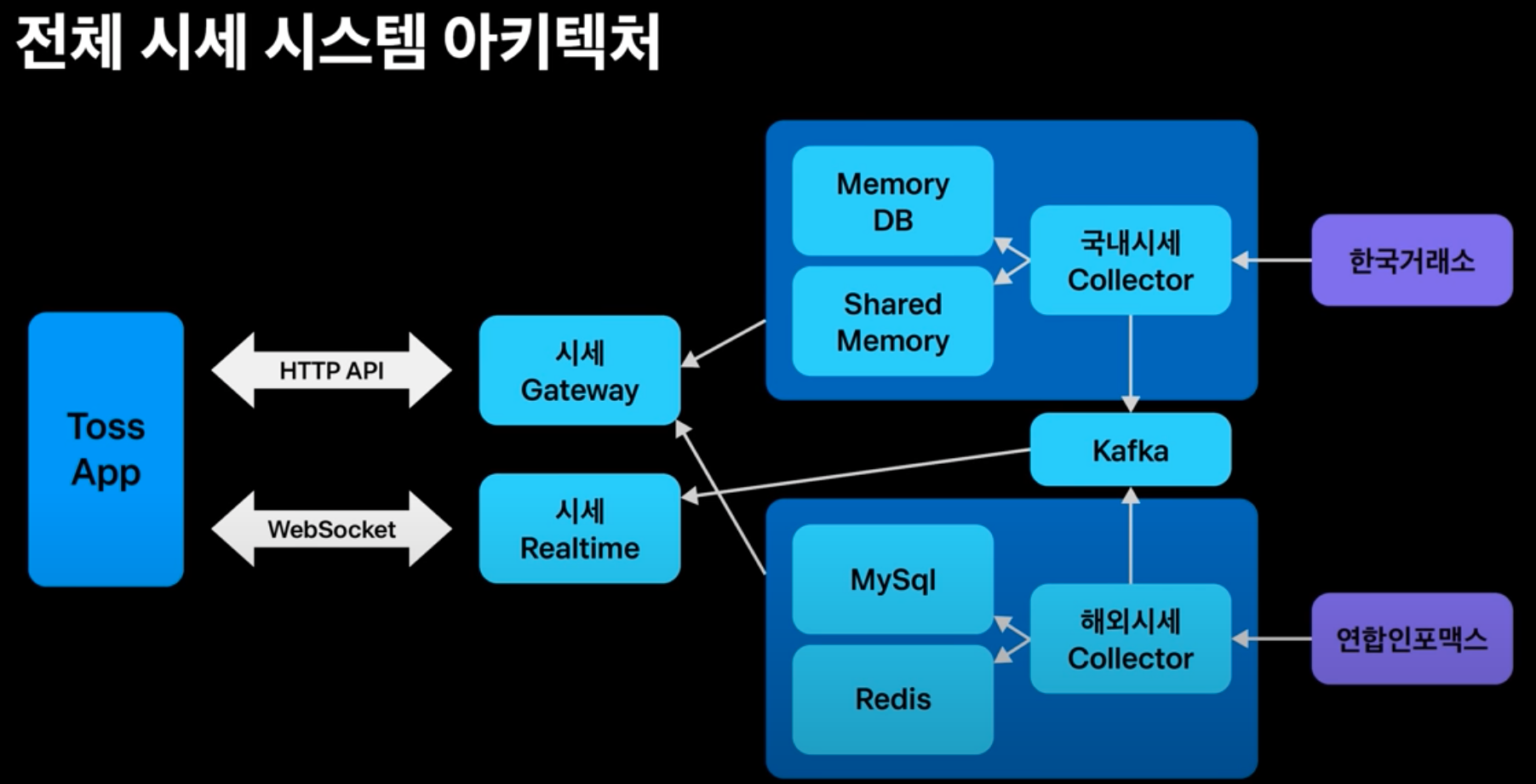
- API Polling 방식으로 실시간 시세를 구현했지만, 좀 더 좋은 사용자 경험을 위해 WebSocket 방식을 선택.
- 양방향 통신이 아닌 단방향만 필요하다면 SSE(Server Sent Event)도 좋은 선택입니다.
(방화벽 등 보안 설정 용이) - WebSocket 방식이 지연되는 경우 API Polling을 사용하는 방법으로 구축 초기에 아주 유용하게 사용되습니다.
- 양방향 통신이 아닌 단방향만 필요하다면 SSE(Server Sent Event)도 좋은 선택입니다.
트러블 슈팅
- Connection 부하 분산을 위해 Round Robin 방식과 Least Connection 방식을 혼합해서 사용.
- WebSocket 사용 시 비정상 종료에 대한 예외 처리를 잘해야 합니다.
- 대용량 트래픽 처리 시 방화벽과 보안 장비의 처리량도 고려해야 합니다.
- 스케일 아웃의 유연함을 위해 온프레미스 환경에서 클라우드 환경으로의 이전을 고려하고 있습니다.
처음에는 API Polling 방식으로 접근했다는 것에 놀랐고, 이미 완성된 기능이 있음에도 불구하고 좋은 사용자 경험을 위해 WebSocket 방식으로 재 구현했다는 점에서 두 번 놀랐습니다.
만약 내가 저 상황이라면 그렇게 선택할 수 있을까? 고민하게 됩니다.
애플 한 주가 고객에게 전달 되기까지
동시성을 다루기 위한 Lock 사용 방법
- 보편적인 락 구현은 DBMS에 락을 위한 테이블을 생성하고 트랜잭션 시작 시 테이블에 락을 잡습니다.
- 독립적인 DBMS를 사용하는 MSA 환경에서는 적절하지 않기에 Redis 기반의 분산 락을 설계했습니다.
- 만약의 상황을 위해 낙관적인 락을 추가로 구현했습니다.
해외 구간 네트워크 지연을 보완하기 위한 브로커 전략
- 매매 서버에서 고객의 요청을 받는 스레드와 브로커에게 요청하는 스레드를 분리하고 비동기 처리합니다.
- 브로커로의 요청을 멱등하게 구현하고, 재시도 주기를 적절하게 설정합니다.
브로커 의존성 격리하기
- 매매 서버에서 브로커로의 연결을 인터페이스로서 매매 요청 서버로 분리합니다.
- 이를 통해 도메인 로직은 매매 서버에 응집되고, 처리량과 스케일 아웃의 책임은 매매 요청 서버로 격리됩니다.
- 마찬가지의 이유로 체결 수신의 서버 또한 분리되어 있습니다.
- 체결 수신 서버는 매매 서버로 응답하기 전에 DB 기록을 함으로써 다양한 Fail Over 전략의 선택이 가능합니다.
동시성과 브로커는 최근 가장 관심 있는 주제이기에 아주 재미있게 봤습니다.
특히 브로커로의 접근을 스레드 단위로 분리하고, 매매 서버와 매매 요청 서버를 물리적으로 분리한 것이 인상적입니다.
Java Native Memory Leak 원인을 찾아서
개인적으로 Memory Leak에 관심이 있지만 제가 일하는 환경과는 조금 거리가 있는 주제이기에 정리하지는 않습니다.
하지만 글로만 봤었던 소스 변경 없이도 GC나 컴파일러 변경만으로도 튜닝이 가능하다는 것에 대한 실 사례를 보니 조금 신기했습니다.
번외로 Heap Dump 분석 툴인 VisualVM의 세팅과 분석한 기록을 남깁니다.
https://hyune.gitbook.io/hyune-wiki/framework-and-library/monitoring/visualvm
어떻게 안정적인 서비스를 빠르게, 자주 출시할 것인가?
- MSA 환경에서의 복잡한 프로젝트 세팅 시간을 줄이기 위해 Boilerplate Project를 운영합니다.
- 사내 프로젝트의 세팅을 균일화하여 관리하였기에, 최근 log4j 취약점 이슈일 때도 일괄 수정 배포가 용이했습니다.
- CI/CD는 yaml을 통해 관리하기 쉬운 GoCD와 Git Action을 활용합니다.
- 배포 시 쿠버네티스와 Istio를 통해 비율 단위의 트래픽 조절이 가능합니다.
- MSA의 가장 큰 어려움 중 하나인 분산 추적 시스템을 자체 구현했고 Alert도 구현하였습니다.
익히 알고 있는 내용 위주였지만 빅테크의 인프라, CI/CD 관리는 새삼 대단하다고 느꼈습니다!
아쉬운 점은 서버 단위의 설정 관리 방법에 대한 얘기가 없었습니다.
(Spring Cloud Config Server 같은 것을 사용할까?)
번외로 현재 재직 중인 회사에서는 분산 추적 시스템을 Datadog으로 관리합니다.
https://hyune-c.tistory.com/entry/Datadog-%EC%97%90%EC%84%9C-GraphQL-%EB%AA%A8%EB%8B%88%ED%84%B0%EB%A7%81-%EB%A7%9B%EB%B3%B4%EA%B8%B0
'Study' 카테고리의 다른 글
| Spring Cloud OpenFeign + WireMock Test (3) | 2023.02.05 |
|---|---|
| INSERT INTO SELECT SHARED LOCK은 레코드 락으로 작동하는가? with MySql (0) | 2022.07.06 |
| for vs stream (0) | 2022.06.01 |
| Entity의 field type은 무엇이 적합할까? (0) | 2022.05.25 |
| 분산 트랜잭션 설계하기 (초급) (0) | 2022.05.09 |