
기술 영상의 요약이나 후기는 웬만하면 작성하지 않는 편입니다. 하지만 우아콘 2020의 이동욱 님 발표 영상은 하나하나가 너무나도 실무적이고 주옥같은 내용들 뿐이라서 꼭 기억하고 싶은 마음에 정리해봅니다.
테스트 환경
- OpenJDK 1. 8.0_252
- Querydls_JPA 4.2.1
- AWS Aurora MySQL 5.6 1.19.6
1. 워밍업
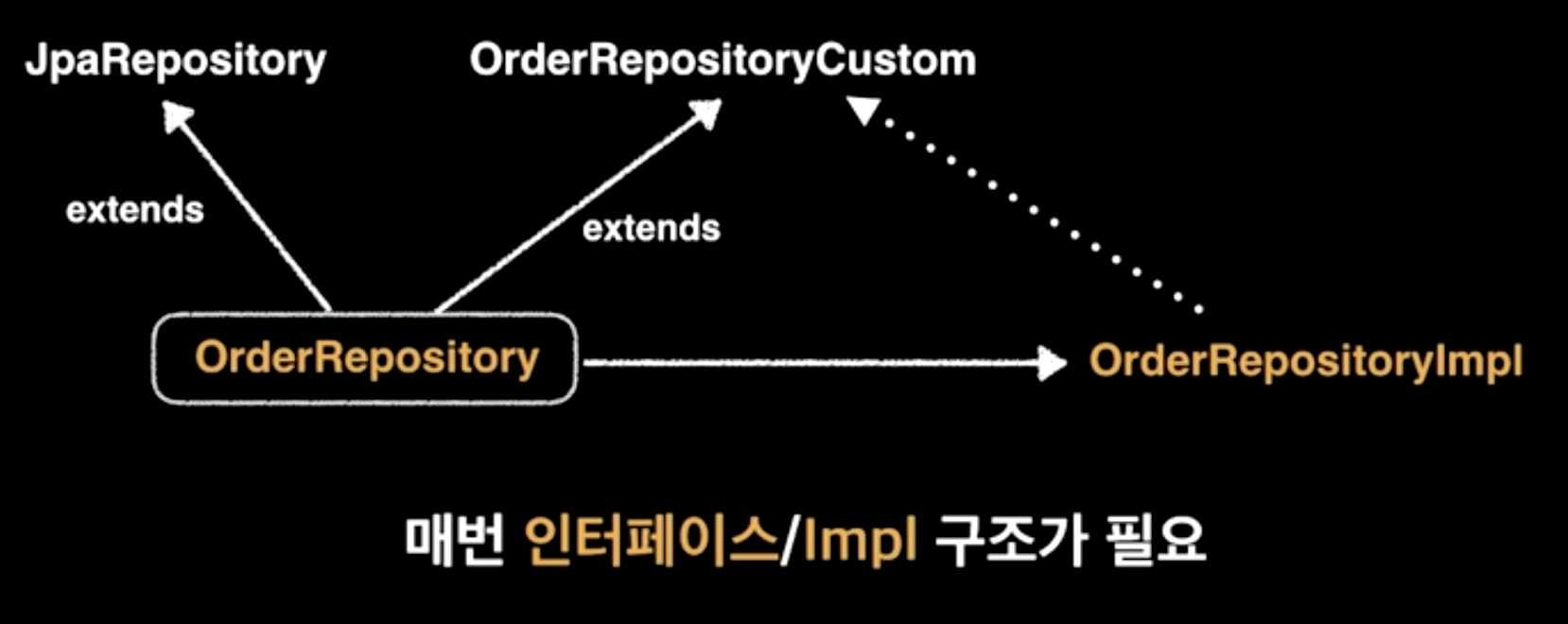
extends / implements 사용하지 않기
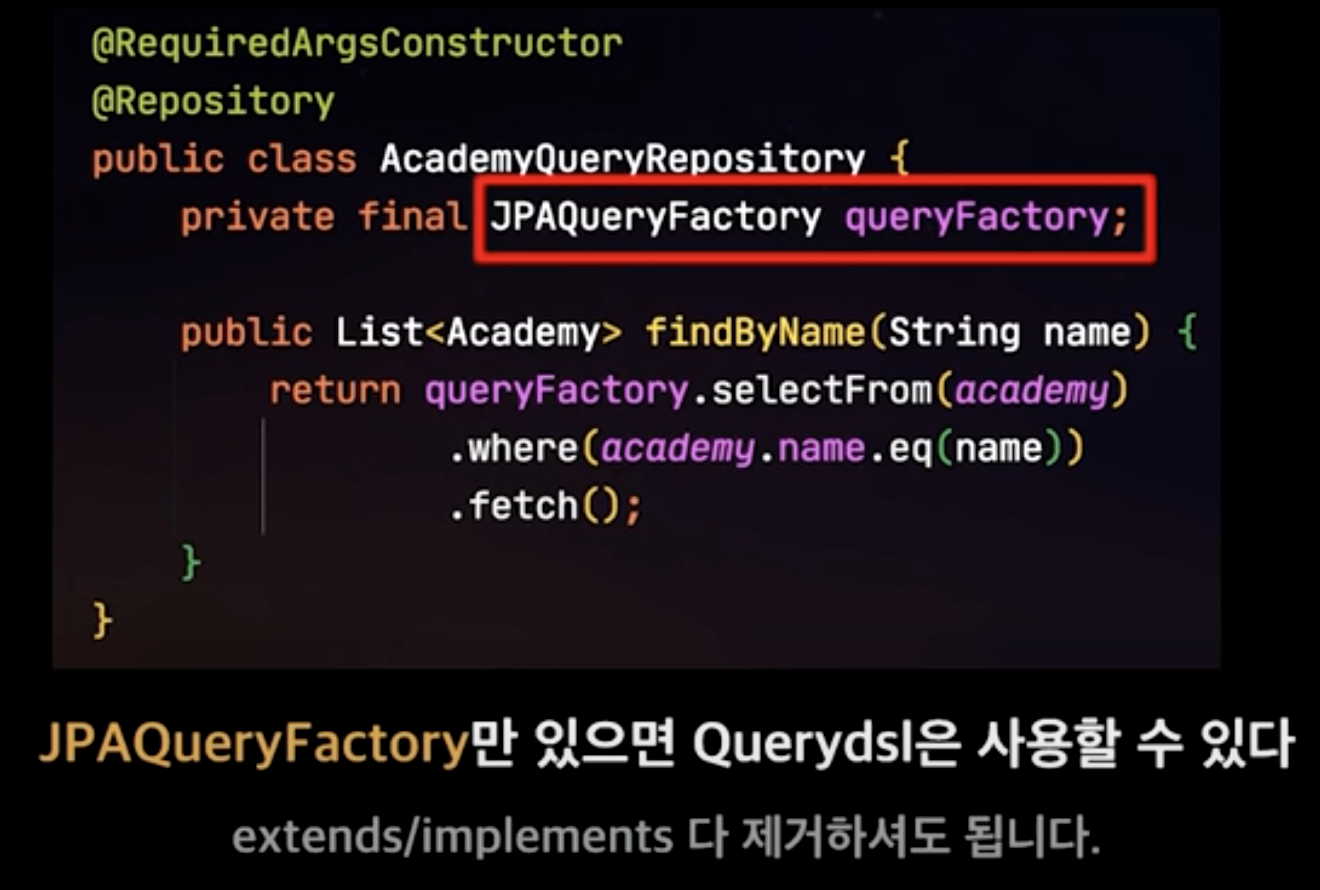
발표 자료에는 없지만 JPAQueryFactory를 Bean으로 설정해주는 작업이 필요합니다.
@Configuration
public class QueryDslConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}
}
영상을 보면서 회사 코드와 사이드 프로젝트들을 점검해보니, 모두 extends/implements를 사용하고 있었습니다. 아마 김영한 님의 강의에서 가져온 것 같습니다.
그리고 사이드 프로젝트에서는 Configuration으로 했지만, 회사코드에서는 각 Impl에서 new JPAQueryFactory(em); 를 하고 있었어 리팩토링 해야겠다고 생각했습니다.
하지만 아무리 생각해봐도 영상 내용으로의 개선이 더 낫다는 생각이 들지 않았습니다.
Custom으로 선언하고, Impl에서 구현하는 것이 클래스는 많아질지라도 유지보수 편의성을 위해 역할을 나누고 가독성을 향상하는 것이 더 좋다고 생각해서였습니다.
마침 댓글을 보니 저와 비슷한 생각을 하신 분이 있어 남깁니다.

동적 쿼리

링크의 블로그에 좀 더 많은 내용이 있습니다.
[Querydsl] 다이나믹 쿼리 사용하기
안녕하세요! 이번 시간에는 Querydsl에서의 다이나믹 쿼리를 어떻게 작성하면 좋을지에 대해 진행합니다. 처음 Querydsl을 쓰시는 분들이 가장 많이 실수하는 부분이니 그럼 시작합니다! 모든 코드
jojoldu.tistory.com
2. 성능개선 - Select
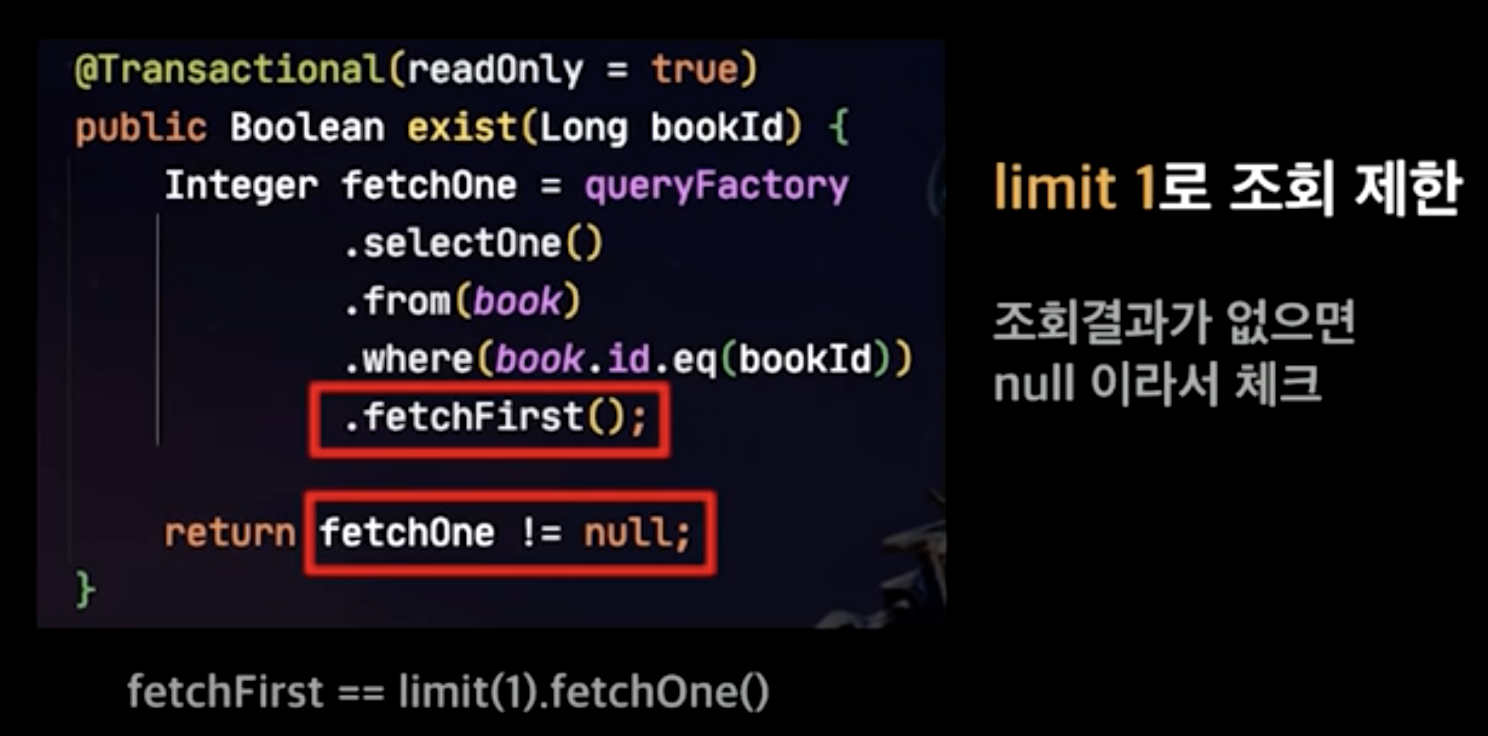
Querydsl의 exist 금지
exist는 조건에 맞는 값을 찾으면 바로 반환하지만 count 쿼리는 전체 행을 모두 조회함으로 성능이 떨어지며, 이 차이는 스캔 대상이 앞에 있을수록 커집니다.

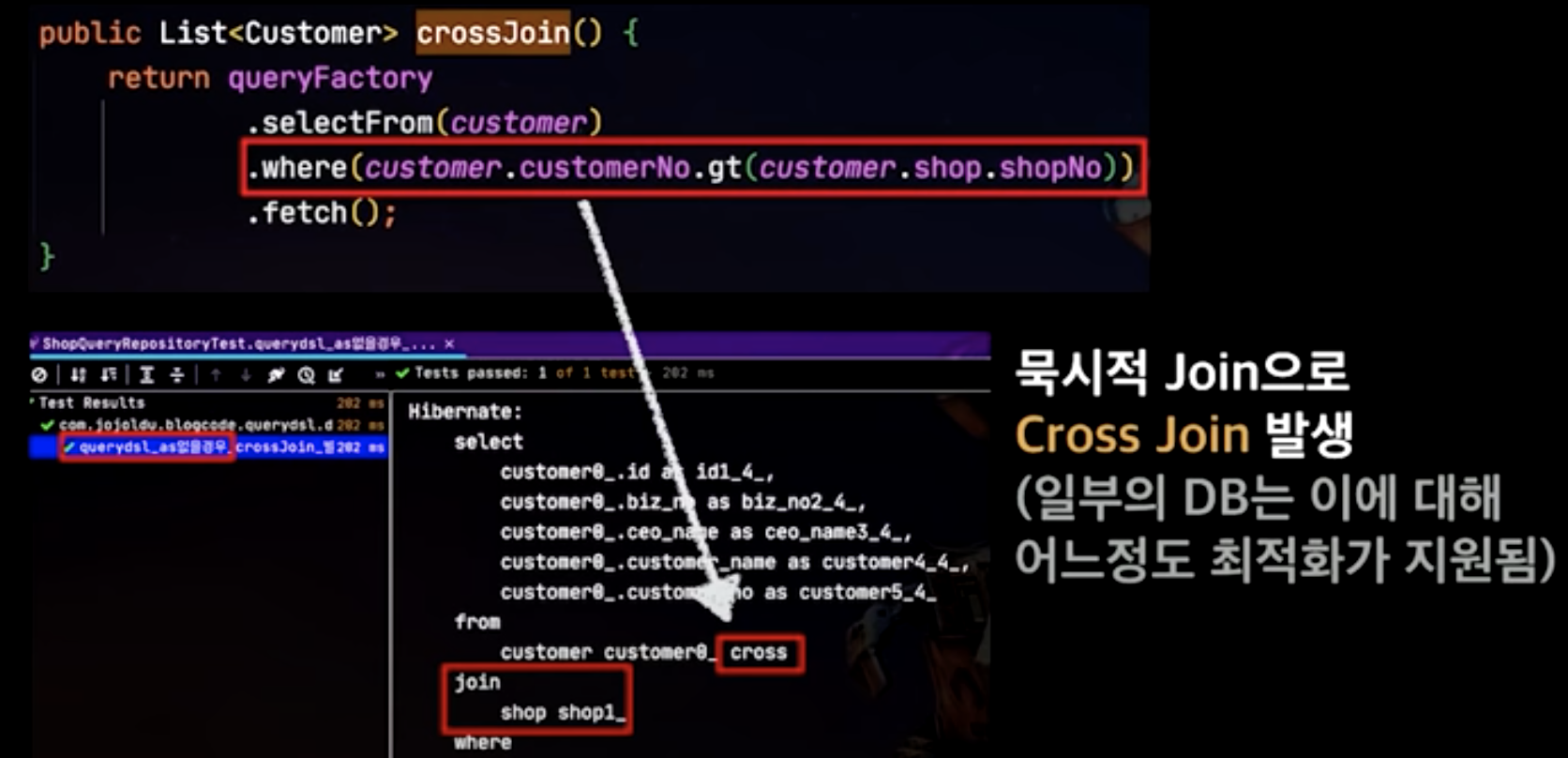
cross join 회피
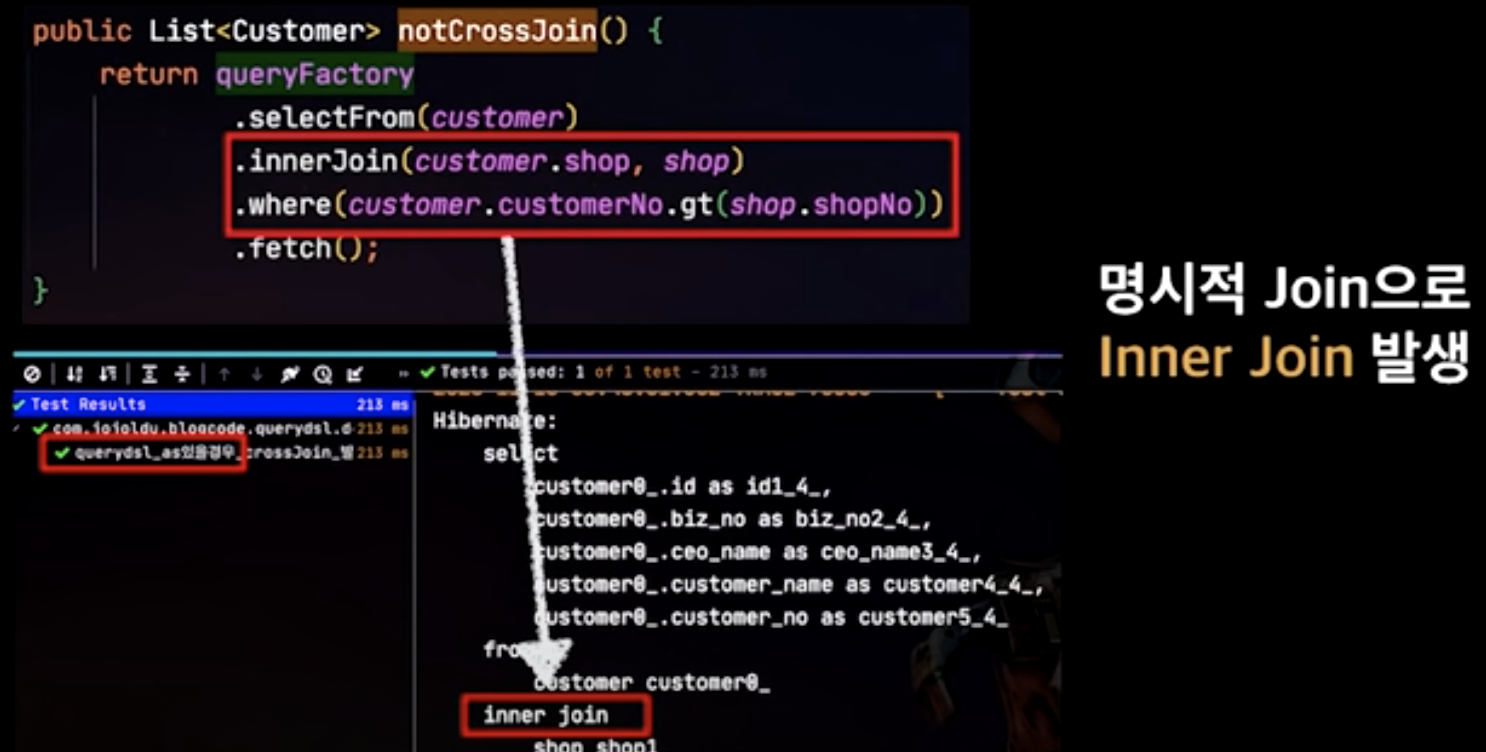
Entity 보다는 Dto를 우선
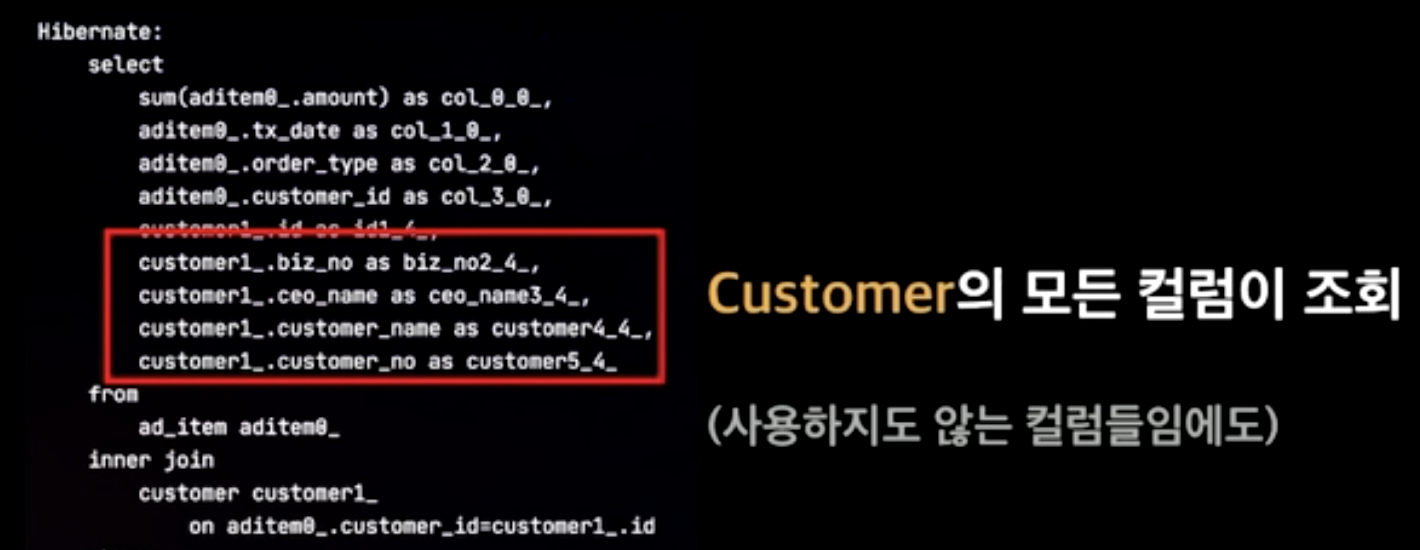
Entity를 직접 조회하면 단순 조회 기능에서의 성능 이슈 요소가 있습니다.
- 하이버네이트 1차, 2차 캐시 문제 발생
- 불필요한 칼럼을 조회합니다.
- @OneToOne N+1 쿼리 발생
아래에서는 이슈를 해결할 수 있는 몇 가지 방법들을 소개합니다. 결론적으로 실시간으로 Entity 변경이 필요한 경우엔 Entity를, 성능 개선이나 대량의 데이터 조회가 필요한 경우엔 Dto를 조회하는 것을 추천합니다.




N+1 문제는 @OneToOne(fetch = FetchType.LAZY) 설정으로도 해결되지 않으며, Fetch Join 의 사용을 추천합니다.
링크의 블로그에 좀 더 많은 내용이 있습니다.
[JPA] @OneToOne에서 Fetch 전략을 Lazy로 설정했을때 발생하는 이슈
Lazy Loading JPA의 유일한 단점은 사용하기 쉬운만큼 성능적인 측면에서 발생할 수 있는 이슈를 간과하기 쉽다는 것인데, 성능이 안나올때 가장 먼저 고려해봐야할 부분이 즉시로딩(EAGER LOADING)으로
1-7171771.tistory.com


Group By 최적화
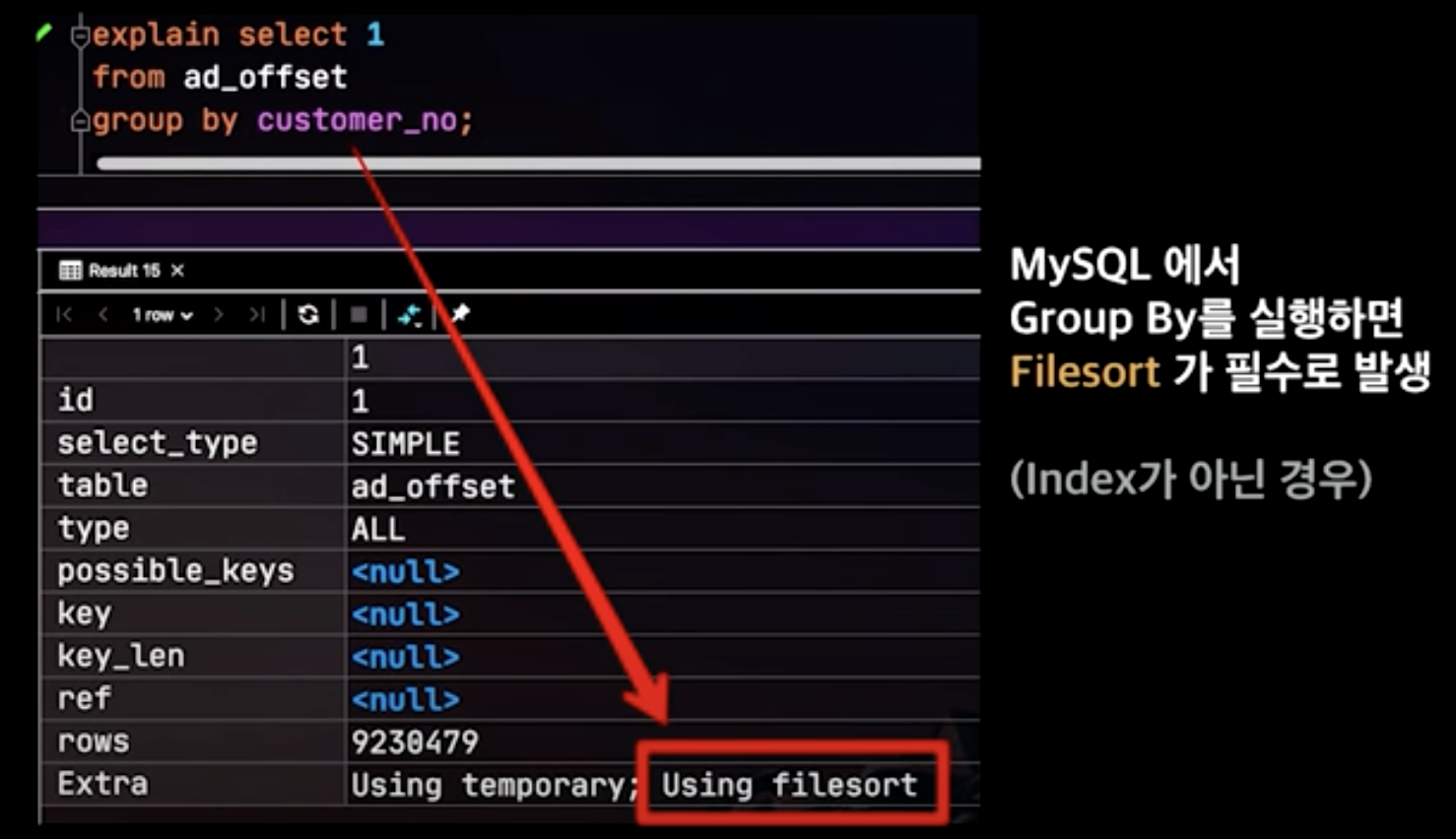
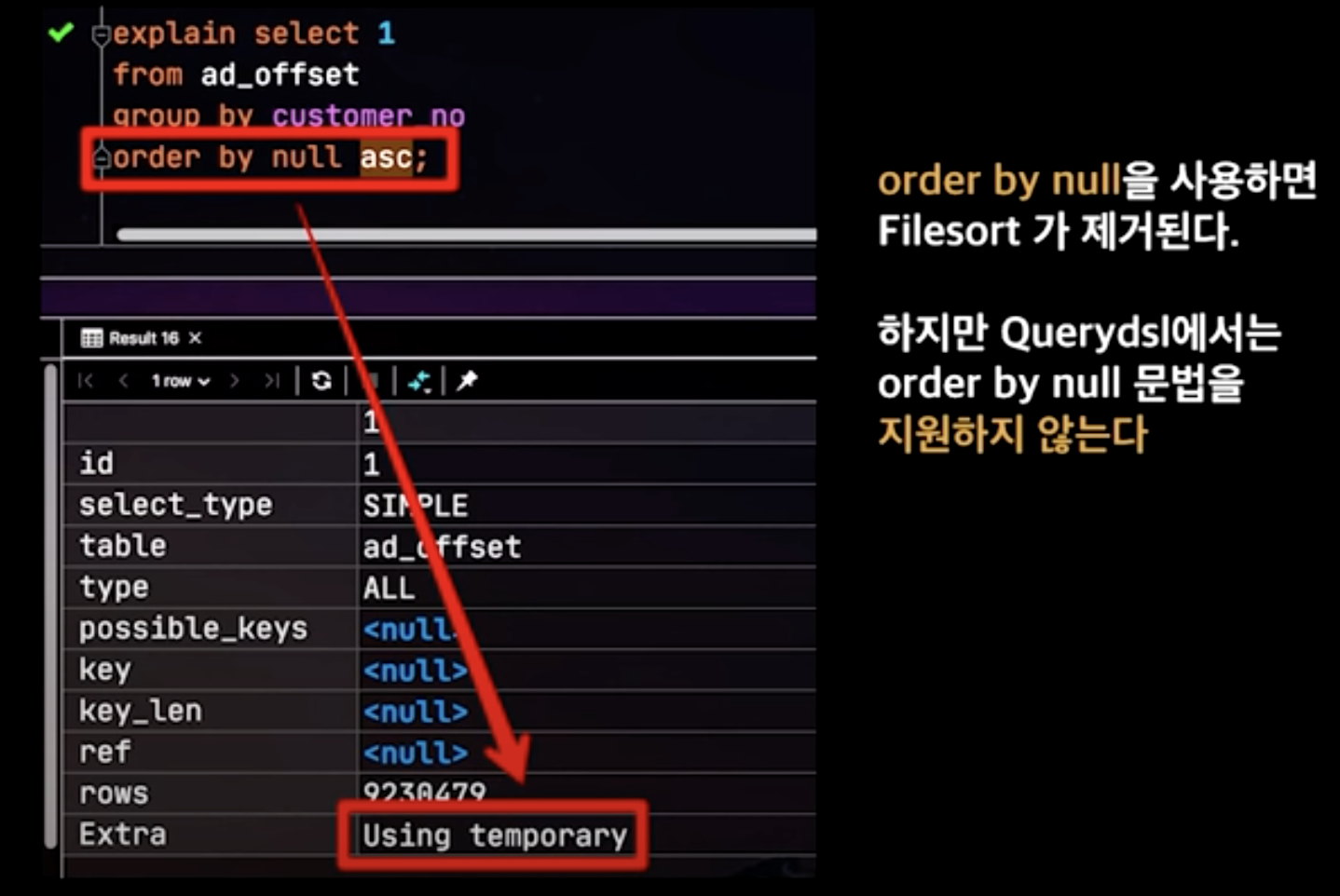
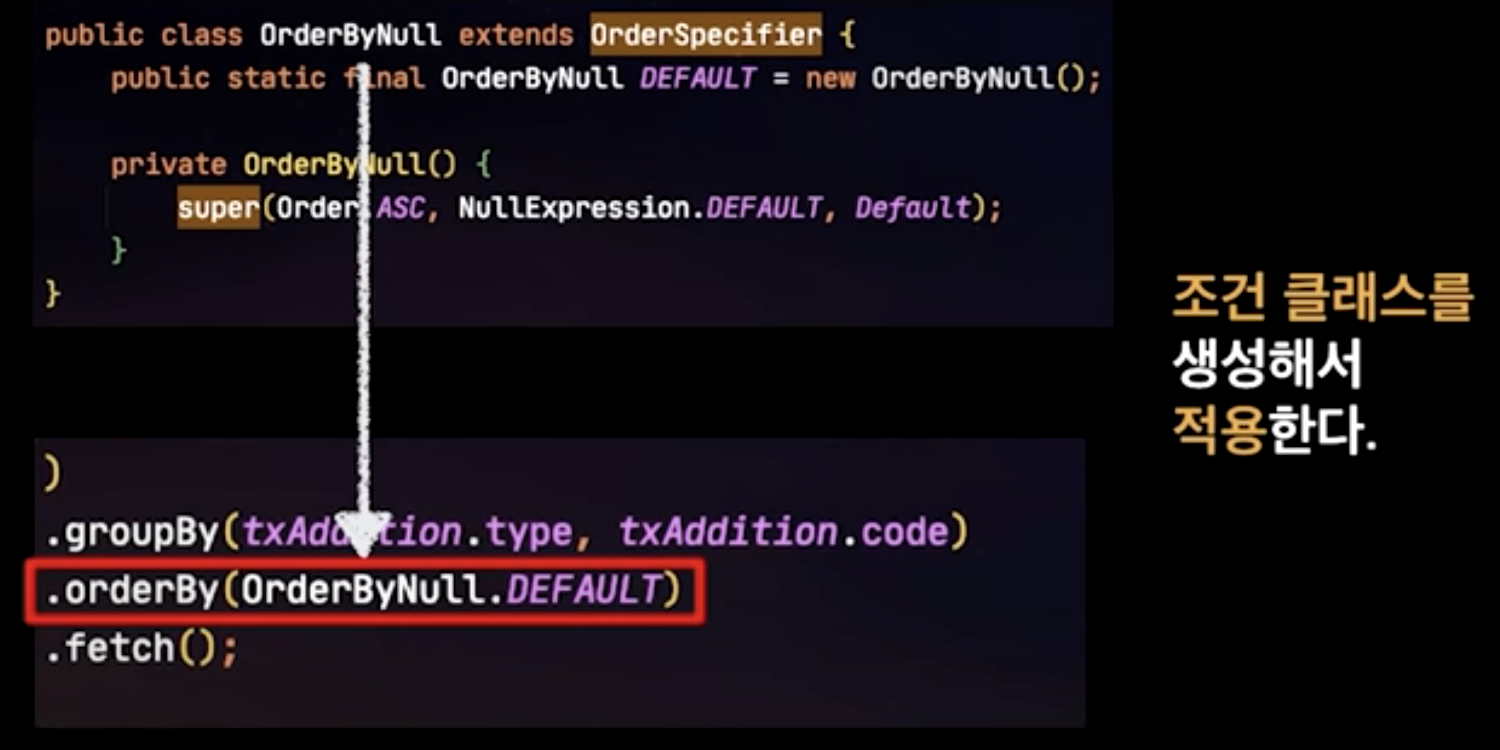
Using filesort는 정렬이 필요한 데이터를 메모리에 올리고 정렬 작업을 수행한다는 의미로, 이미 정렬된 인덱스를 사용함으로써 해결할 수 있습니다. 영상에서는 우리가 사용하는 모든 Group By 가 index를 탄다는 보장이 없기에 말하고 있습니다.
하지만 8.0 이상을 사용하는 환경이라면 더 이상 고려하지 않아도 됩니다.
Previously (MySQL 5.7 and lower), GROUP BY sorted implicitly under certain conditions. In MySQL 8.0, that no longer occurs, so specifying ORDER BY NULL at the end to suppress implicit sorting (as was done previously) is no longer necessary. However, query results may differ from previous MySQL versions. To produce a given sort order, provide an ORDER BY clause.
MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.16 ORDER BY Optimization
8.2.1.16 ORDER BY Optimization This section describes when MySQL can use an index to satisfy an ORDER BY clause, the filesort operation used when an index cannot be used, and execution plan information available from the optimizer about ORDER BY. An ORDER
dev.mysql.com
마지막으로 Paging 이 필요하지 않고 정렬 건수가 적다면 WAS에서 정렬하는 것을 추천합니다.
일반적으로 WAS 리소스가 DB 리소스보다는 여유 있고 저렴하기 때문입니다.
커버링 인덱스


커버링 인덱스를 사용할 땐 inline view (from 절의 subQuery)에서 커버링 인덱스를 통해 필터를 하도록 하는 게 일반적이지만, JPQL은 from 절의 서브 쿼리를 지원하지 않아 직접 구현해야 합니다.
링크의 블로그에 좀 더 많은 내용이 있습니다.
1. 페이징 성능 개선하기 - No Offset 사용하기
일반적인 웹 서비스에서 페이징은 아주 흔하게 사용되는 기능입니다. 그래서 웹 백엔드 개발자분들은 기본적인 구현 방법을 다들 필수로 익히시는데요. 다만, 그렇게 기초적인 페이징 구현 방
jojoldu.tistory.com
1. 커버링 인덱스 (기본 지식 / WHERE / GROUP BY)
일반적으로 인덱스를 설계한다고하면 WHERE 절에 대한 인덱스 설계를 이야기하지만 사실 WHERE 뿐만 아니라 쿼리 전체에 대해 인덱스 설계가 필요합니다. 인덱스의 전반적인 내용은 이전 포스팅을
jojoldu.tistory.com
3. 성능 개선 - Update/Insert
일괄 Update 최적화

- Dirty Checking - 실시간 비즈니스 처리, 실시간 단건 처리
- Querydsl.update - 대량의 데이터를 일괄로 Update 처리
주의할 점은 일괄 업데이트는 영속성 컨택스트의 1차 캐시 갱신이 안됨으로 Cache Eviction 이 필요합니다.
JPA로 Bulk Insert는 자제한다.

// 3번의 DB 연결이 필요한 비효율적인 insert
INSERT INTO table_a (subject, content)
VALUES ('sub1', 'con1');
INSERT INTO table_a (subject, content)
VALUES ('sub2', 'con2');
INSERT INTO table_a (subject, content)
VALUES ('sub3', 'con3');
// 1번의 DB 연결로 개선한 효율적인 insert
INSERT INTO table_a (subject, content)
VALUES ('sub1', 'con1'),
('sub2', 'con2'),
('sub3', 'con3');즉 위와 같은 성능 개선을 할 수 없다는 뜻입니다.
영상에서 JdbcTemplate를 말하지만 type safe 하지 않은 단점과 함께 EntityQL를 소개합니다. 하지만 이도 설정과 사용법에 단점을 가지고 있으므로 선택적으로 사용해야 된다고 말합니다.
저는 Spring 진영에서 공식적으로 밀어주는 JOOQ를 추천합니다. starter 가 존재하기에 세팅도 쉽고, 사용 경험도 매우 좋았습니다.
마무리
JPA, QueryDSL은 편리하지만 결국 DB에 쿼리를 날려서 조회하는 것이기에, 그 과정을 잘 이해하고 고민해야 합니다.
생각해보니 지금까지는 데이터가 적은 환경에서만 일하고 공부했기에, JPA를 심도 있게 사용하지 못했었습니다. 그러다 보니 문법과 기본적인 사용법은 알지만, 실무에서의 고급 활용을 위한 이해가 부족합니다.
물론 지금의 회사에서도 JPA, Querydsl을 사용하긴 하지만, 아직은 JOOQ의 사용이 더 많습니다. DB 구성이 ORM 기술에 적합하지 않게 설계되어있고, Procedure도 많이 존재하기 때문이라고 생각합니다. 무엇보다도 사용하는 사람이 기술에 대한 이해도가 높고 잘 사용해야 되는데 저부터도 이해도가 부족하다는 것을 느꼈습니다.
다행히도 내년의 회사 과제 중 하나로 MSA 구성이 있습니다. 이때 성능 분석도 도입하고, 열심히 공부해서 JPA를 좀 더 적극적으로 사용해보고 싶습니다.
파이팅!!
'Study' 카테고리의 다른 글
| 대량 데이터 조회와 유지보수는 어떻게 해야될까? (0) | 2022.04.02 |
|---|---|
| 마이크로 서비스도 리소스 동기화가 필요할까? (2) | 2022.03.04 |
| String 을 잘 써보자 (0) | 2021.10.16 |
| @Component vs @Configuration (0) | 2021.09.25 |
| mongoDB tutorials (0) | 2021.05.18 |