GC에 익숙한 사람이라면 모두 Generational GC가 최고라고 이야기합니다.
'generational hypothesis는 대부분 상황에서 Young Object는 Old Object 보다 죽을 가능성이 클 것으로 내다본다.' 2008년에는 맞는 말이었죠. 하지만 지금은 설득력이 떨어집니다.
Red Hat 개발자 Christine Flood - DevNation 2016 中
기술의 발전과 시장의 변화에 따라 과거에는 옳았던 것이 지금은 재해석되고 있습니다.
클라우드의 도입으로 어려웠던 확장/고가용의 기술이 쉬워지고, 하드웨어의 비용이 낮아진 것이 하나의 예입니다.
회사의 성장에 따라 다뤄야 하는 데이터는 기하급수적으로 늘어나고 기존의 방법으로는 해결하기 힘든 순간이 옵니다.
지금 다니는 회사에도 그 시점이 다가오고 있습니다.
물론 좋은 아이디어들이 많이 있지만, 우선 순위가 다른 지금의 회사에 그대로 적용하는 것은 꽤 어려운 일 입니다.
그렇기에 기술 부채는 계속 쌓이고 있고, 응급조치만으로는 할 수 없는 시점이 다가오고 있습니다.
저는 백엔드 엔지니어로서 그때를 위해 기술을 재해석하고 지금에 적절한 기술을 준비하는 과정을 기록합니다.
지금의 개발 & 조회 환경
배경
- 각각의 플랫폼들은 모놀리식으로 개발되어 있음
- 비슷한 데이터가 독립적으로 존재하고 있으며 호환되지 않음
- 대량 데이터를 다룰 수 있는 인력 부재
내가 소속되어 있는 플랫폼 P의 환경
- 입점된 대형 업체는 1개뿐임에도 불구하고 간헐적인 속도 이슈 발생
- 인덱스 수정, 최대 조회 기간을 1달로 제한하는 등의 단발성 응대로 해결
- 상반기 내 다수의 대영 업체 입점 예정
- 대부분의 조회 로직이 영속성 레이어에 집중되어 있음
- 초대형 쿼리로 구성된 로직은 수정 난이도가 높고 높은 업무 이해도가 요구됨
- 데이터의 상태가 개별 column으로 관리되며 비슷한 상태가 중복되기도 함 (ex. SYSTEM_USER_YN)
- 도메인 로직 정의보다 DB 테이블 정의가 선행되고 그것에 맞추는 개발을 하고 있음
- 확장성보다는 성능과 개발 속도를 중시한 단일 테이블 형태가 많음
- read only DB에 대한 필요성은 공감되고 있지만 실 적용하지 못하고 있음
- GraphQL의 특성을 살리지 못하고 화면 별로 특화된 대형 조회 쿼리 형태로 운영되고 있음
- 오히려 학습과 문제 해결 난이도만 높아짐
개선을 위한 아이디어
이미 알려진 아이디어는 많습니다.
하지만 내가 일하는 환경에 적용할 수 있도록 재해석하는 것은 완전히 다른 영역입니다.
1. 영속성 레이어에 집중된 로직을 분리
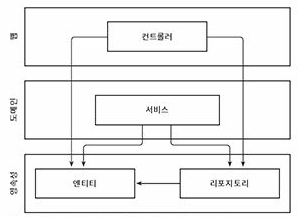
제가 생각하는 초대형 쿼리가 생겨나는 원인은
- 요구 사항의 변경을 도메인이 아닌 쿼리, 즉 영속성 레이어에서 해결하고 있습니다.
- 보통 높은 이해도가 필요한 복잡한 업무 환경에서 나오는 현상이며, 지금의 빠른 개발을 위해 쿼리의 일부만 수정하거나 인덱스를 통해 해결하기에 해당 기능에 특화된 대형 쿼리로 작성되곤 합니다.
- 이 로직은 재사용이 불가능하고 높은 결합도를 가집니다.
- 수정을 위해서는 문맥 이해와 영향도 체크 후 분리, 추상화 비용이 개발에 준하는 수준으로 발생됩니다.
과거에는 맞습니다.
소프트웨어는 비교적 짧은 수명을 가지고 워터폴 방식으로 개발되었습니다.
- 변경은 비교적 적거나 보수적으로 수용되었고, 변경 난이도가 일정 수치를 넘어서면 차세대 개발로 대체되었습니다.
- 자연스럽게 비교적 긴 수명의 DB와 높은 비용의 하드웨어 집중된 개발이 되었습니다.
- 한 가지 예로 성능 향상을 위해 join을 줄이는 단일 테이블 전략이 많이 사용되었습니다.
지금은 다릅니다.
높아진 개발 비용과 니즈가 다양해진 지금의 환경에서는 변경 난이도를 낮추는 것이 더 중요해졌습니다.
- 도메인 레이어에서 범용 로직을 조립하는 DDD 이론이 나왔습니다.
- 클라우드가 등장하면서 확장성이 용이해지고 인프라 의존도가 줄었습니다.
백엔드 개발 측면에서 단적인 예를 들자면
- 과거에는 높은 컴퓨팅 비용이 드는 stream 대신 for문을 사용해야 된다는 의견도 있었습니다.
- 지금은 하드웨어 활용으로 개발 난이도를 낮추고, 나아가 함수형 패러다임으로의 변경까지 일어나고 있습니다.
저와 비슷한 생각으로 레이어를 나눈 좋은 글이 있어 공유합니다.
Layered Architecture Deep Dive
최근 진행 중인 프로젝트는 Layered Architecture를 선택하여 패키지를 구성하고 개발하였습니다.
msolo021015.medium.com
2. 성능 개선을 위한 방법
WAS 스케일 업, 스케일 아웃(Scale-up, Scale-out)
클라우드 환경이라면 가장 영향도가 적은 방법으로 인프라 성능을 확장시키는 것입니다.
- EC2 개별 구성-> Elastic BeanStalk -> ECS - Fargate -> Kubernetes 순으로 기술을 도입할 수 있습니다.
- Elastic Load Balancer를 통해 트래픽을 분산시키고, Auto Scaling을 통해 스케일 업을 자동화할 수 있습니다.
- 업무 성격에 따라 T 타입 인스턴스를 통한 버스트 기능을 활용하는 방법도 있습니다.
DB 스케일 업, 스케일 아웃(Scale-up, Scale-out)
- Replication DB
- CUD 로직을 수행하는 master DB와 R 로직을 수행하는 복제 DB를 구성하는 방법으로 확장성이 용이합니다.
- 단점으로는 동기화에 시간이 걸리며, DB 연결의 추가 개발과 인프라 구성이 필요합니다.
- RDB를 사용하고 있다면 Amazon Aurora 도 좋은 선택입니다. (2021.11부터 MySql 8.0 지원)
파티셔닝(Partitioning), 샤딩(Sharding)
- 과거에는 직접 구성해야 됐지만, 지금은 DB나 프레임워크에서 지원해주기도 하는 전통적인 분산 처리 기술입니다.
- 하지만 운영 난이도가 높고 RDB가 대세였던 시기에 분산 처리를 하기 위해 나온 기술이기에, 최근에는 분산 처리를 전제로 한 기술이 권장되고 있습니다.
- NoSQL, CDC(Changed Data Capture), ETL
ETL (Extract, Transform, Load), Data warehouse
- 비슷하지만 다른 데이터를 의미있게 재구성해야하는 현대의 개발에 가장 활용성 높은 기술 중 하나입니다.
- 과거에는 배치성의 개발이 필요했지만 현재는 AWS Redshift, Athena 등을 통해 편리하게 작업할 수 있습니다.
- 단점으로는 학습과 운영 난이도가 높으며 데이터를 집계, 재배열하는 시간이 필요해 실시간 처리는 힘든 기술입니다.
CQRS (Command and Query Responsibility Segregation)
명령과 조회의 책임 분리를 하는 패턴으로 앞에 소개한 방법 중 가장 적은 영향도와 개발 비용이 듭니다.
- CUD 로직은(등록, 수정, 삭제) Command로 모아 도메인 로직에 응집시키고 ORM 기술을 활용합니다.
- R 로직은(조회) Query로 모으며 필요에 따라 native query를 사용하기도 합니다.
3. 지금에 적절한 기술을 선별하는 것
알려진 기술들은 이미 많습니다. 중요한 것은 지금에 적절한 기술을 선별하는 것입니다.
플랫폼 P는 사용량이 적음에도 불구하고 성능 이슈가 발생하고 있으며, 대형 업체의 추가 입점이 예정되어 있습니다.
이대로라면 이미 제한한 최대 조회 범위를 더 줄여야 하고, 적절하게 조절하지 못했다면 장애로 번질 수도 있습니다.
백엔드 아키텍처만을 수정합니다
가장 영향도가 낮은 방법으로 CQRS의 분리와 도메인 레이어의 도입이 있습니다.
- 개발의 수정 난이도는 낮춰주지만, 이미 부하가 발생하고 있는 환경에 드라마틱한 효과를 기대하기는 힘듭니다.
- 아키텍처의 복잡도가 높아지는 만큼 혼란을 막기 위해 컨벤션 정의가 선행되어야 합니다.
대형 업체별로 테이블을 분리합니다
기존에는 몇 개의 거대한 테이블에 데이터와 복잡한 조회 로직이 모여 있었기 때문에 조회에 문제가 되었습니다.
따라서 대형 업체별로 테이블을 분리하는 방법이 있습니다.
하지만 이미 구현된 거미줄 같은 로직에 연관된 테이블을 대형 업체 별로 추가해야 되기에 개발 복잡도가 급격하게 높아짐으로 장기적인 해결책이라고 볼 수 없습니다.
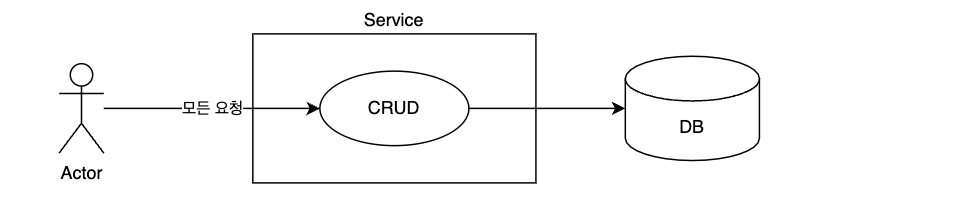
가장 큰 문제는 CRUD가(Create, Read, Update, Delete) 모두 하나의 서비스에서 일어나고 있다는 것입니다.
즉 지금의 구성은 동기화에는 좋지만 확장과 부하에 약하고, 유지보수의 용이성의 고려도 필요합니다.
성능 향상과 유지보수성을 모두 만족시키기 위해서는 패러다임을 변경해야 됩니다.
CQRS의 서비스 단위 분리
기존의 업무를 분석하고 재해석하여 CUD와 대용량 R 업무를 구분합니다.
그리고 CUD는 기존의 서비스에서 진행하고, 대용량 R 업무는 서비스를 분리합니다.
테이블 설계 방식 변경
CUD 서비스의 테이블은 확장성이 좋고 ORM 기술 사용에 용이한 조인 테이블 전략으로 설계합니다.
성능이 필요한 대용량 R 업무가 분리되었기에 가능합니다.
Data warehouse 도입
Data warehouse를 도입하여 대용량 R 업무의 조회를 위한 테이블을 독립적인 공간에 구성합니다.
- AWS의 기술을 사용한다면 최근 공개된 AWS Glue Studio의 사용을 고려하는 것도 좋습니다.
- 배치로 구현한다면 NoSQL의 도입도 고려할 수 있습니다.
RDB 수준의 ACID를 준수하지는 않지만 대용량 조회라는 업무 성격상 적합하기 때문입니다.
개선 방향
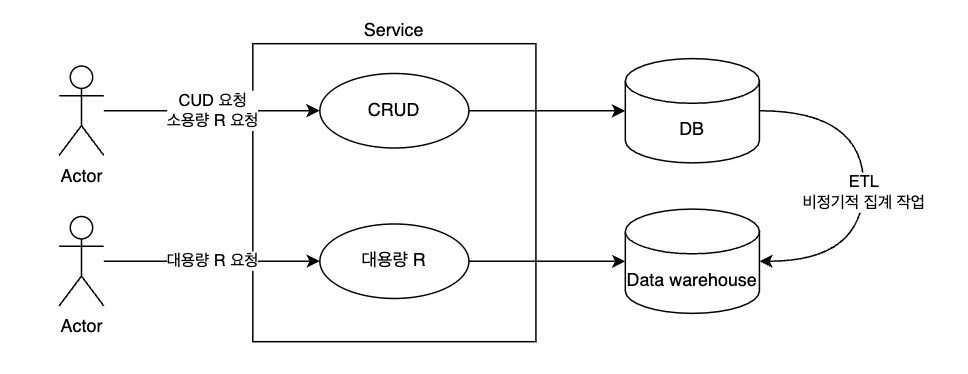

나아가 이기종 플랫폼의 정보를 Data warehouse로 통합할 수도 있습니다.
기타
ETL/Data warehouse 운영의 가장 큰 단점은 실시간 데이터와 집계 과정에서 발생하는 간극입니다.
즉 대용량 조회는 D-2 이전의 데이터만 지원한다와 같은 업무적 합의가 필요합니다.
과거 운영했던 업무 중에 하나를 예로 들면
- 카드사 별 카드 이용내역을 배치를 통해 시간 단위로 별도 시스템으로 집계합니다.
- 카드 이용내역은 즉시 확인 가능하지만, 매입내역은 익일 확인 가능합니다.
마치며
앞에서 말한 것들은 새로운 패러다임을 도입하는 만큼 구성원 모두가 공부해야 되는 양도 많습니다.
저도 아직 이해가 깊지 못하기에 개인적으로 공부하며 최근 맡은 개발과 사이드 프로젝트에서 자체적으로 도입해보고 있습니다.
제가 생각하는 좋은 엔지니어란 정석을 알고 뒤처지지 않으면서도 지금에 적절한 기술을 선택할 수 있는 사람입니다.
그리고 이런 사람들이 모여 좋은 자극을 자발적으로 공유할 때, 모두의 실력이 상향 평준화되고 높은 퀄리티의 결과물이 나올 수 있다고 생각합니다.
좋은 자극을 지속적으로 받을 수 있는 환경을 기대하며 성능 개선에 관련된 영상을 하나 남기고 글을 마칩니다.
'Study' 카테고리의 다른 글
| 분산 트랜잭션 설계하기 (초급) (0) | 2022.05.09 |
|---|---|
| 'AWS와 토스페이먼츠를 통해 E-Commerce 스타트업 혁신하기' 웨비나 후기 (0) | 2022.04.29 |
| 마이크로 서비스도 리소스 동기화가 필요할까? (2) | 2022.03.04 |
| '수십억건에서 QUERYDSL 사용하기' 를 보고.. (2) | 2021.12.19 |
| String 을 잘 써보자 (0) | 2021.10.16 |